Where do these come from? Since most statistical packages calculate these estimates automatically, it is not unreasonable to think that many researchers using applied econometrics are unfamiliar with the exact details of their computation.
For the purposes of illustration, I am going to estimate different standard errors from a basic linear regression model: 

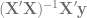
rm(list=ls())
library(foreign)
#load data
children <- read.dta("children.dta")
# lm formula and data
form <- ceb ~ age + agefbrth + usemeth
data <- children
# run regression
r1 <- lm(form, data)
# get stand errs
> summary(r1)
Call:
lm(formula = form, data = data)
Residuals:
Min 1Q Median 3Q Max
-6.8900 -0.7213 -0.0017 0.6950 6.2657
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.358134 0.173783 7.815 7.39e-15 ***
age 0.223737 0.003448 64.888 < 2e-16 ***
agefbrth -0.260663 0.008795 -29.637 < 2e-16 ***
usemeth 0.187370 0.055430 3.380 0.000733 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.463 on 3209 degrees of freedom
(1148 observations deleted due to missingness)
Multiple R-squared: 0.5726, Adjusted R-squared: 0.5722
F-statistic: 1433 on 3 and 3209 DF, p-value: < 2.2e-16
When the error terms are assumed homoskedastic IID, the calculation of standard errors comes from taking the square root of the diagonal elements of the variance-covariance matrix which is formulated:
![E[\textbf{uu}'|\textbf{X}] = \mathbf{\Sigma_{u}}](https://s0.wp.com/latex.php?latex=E%5B%5Ctextbf%7Buu%7D%27%7C%5Ctextbf%7BX%7D%5D+%3D+%5Cmathbf%7B%5CSigma_%7Bu%7D%7D&bg=ffffff&fg=666666&s=0&c=20201002)

![\textrm{Var}[\hat{\mathbf{\beta}}|\textbf{X}] = (\textbf{X}'\textbf{X})^{-1} (\textbf{X}' \mathbf{\Sigma_{u}} \textbf{X}) (\textbf{X}'\textbf{X})^{-1}](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BVar%7D%5B%5Chat%7B%5Cmathbf%7B%5Cbeta%7D%7D%7C%5Ctextbf%7BX%7D%5D+%3D+%28%5Ctextbf%7BX%7D%27%5Ctextbf%7BX%7D%29%5E%7B-1%7D+%28%5Ctextbf%7BX%7D%27+%5Cmathbf%7B%5CSigma_%7Bu%7D%7D+%5Ctextbf%7BX%7D%29+%28%5Ctextbf%7BX%7D%27%5Ctextbf%7BX%7D%29%5E%7B-1%7D&bg=ffffff&fg=666666&s=0&c=20201002)
![\textrm{Var}[\hat{\mathbf{\beta}}|\textbf{X}] = \sigma_{u}^{2}(\textbf{X}'\textbf{X})^{-1}](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BVar%7D%5B%5Chat%7B%5Cmathbf%7B%5Cbeta%7D%7D%7C%5Ctextbf%7BX%7D%5D+%3D+%5Csigma_%7Bu%7D%5E%7B2%7D%28%5Ctextbf%7BX%7D%27%5Ctextbf%7BX%7D%29%5E%7B-1%7D&bg=ffffff&fg=666666&s=0&c=20201002)
In practice, and in R, this is easy to do. Estimate the variance by taking the average of the ‘squared’ residuals 
# get X matrix/predictors X <- model.matrix(r1) # number of obs n <- dim(X)[1] # n of predictors k <- dim(X)[2] # calculate stan errs as in the above # sq root of diag elements in vcov se <- sqrt(diag(solve(crossprod(X)) * as.numeric(crossprod(resid(r1))/(n-k)))) > se (Intercept) age agefbrth usemeth 0.173782844 0.003448024 0.008795350 0.055429804
In the presence of heteroskedasticity, the errors are not IID. Consequentially, it is inappropriate to use the average squared residuals. The robust approach, as advocated by White (1980) (and others too), captures heteroskedasticity by assuming that the variance of the residual, while non-constant, can be estimated as a diagonal matrix of each squared residual. In other words, the diagonal terms in 

# residual vector u <- matrix(resid(r1)) # meat part Sigma is a diagonal with u^2 as elements meat1 <- t(X) %*% diag(diag(crossprod(t(u)))) %*% X # degrees of freedom adjust dfc <- n/(n-k) # like before se <- sqrt(dfc*diag(solve(crossprod(X)) %*% meat1 %*% solve(crossprod(X)))) > se (Intercept) age agefbrth usemeth 0.167562394 0.004661912 0.009561617 0.060644558
Adjusting standard errors for clustering can be important. For example, replicating a dataset 100 times should not increase the precision of parameter estimates. However, performing this procedure with the IID assumption will actually do this. Another example is in economics of education research, it is reasonable to expect that the error terms for children in the same class are not independent.
Clustering standard errors can correct for this. Assume m clusters. Like in the robust case, it is 


# cluster name
cluster <- "children"
# matrix for loops
clus <- cbind(X,data[,cluster],resid(r1))
colnames(clus)[(dim(clus)[2]-1):dim(clus)[2]] <- c(cluster,"resid")
# number of clusters
m <- dim(table(clus[,cluster]))
# dof adjustment
dfc <- (m/(m-1))*((n-1)/(n-k))
# uj matrix
uclust <- matrix(NA, nrow = m, ncol = k)
gs <- names(table(data[,cluster]))
for(i in 1:m){
uclust[i,] <- t(matrix(clus[clus[,cluster]==gs[i],k+2])) %*% clus[clus[,cluster]==gs[i],1:k]
}
# square root of diagonal on bread meat bread like before
se <- sqrt(diag(solve(crossprod(X)) %*% (t(uclust) %*% uclust) %*% solve(crossprod(X)))*dfc
> se
(Intercept) age agefbrth usemeth
0.42485889 0.03150865 0.03542962 0.09435531
For calculating robust standard errors in R, both with more goodies and in (probably) a more efficient way, look at the sandwich package. The same applies to clustering and this paper. However, here is a simple function called ols which carries out all of the calculations discussed in the above.
ols <- function(form, data, robust=FALSE, cluster=NULL,digits=3){
r1 <- lm(form, data)
if(length(cluster)!=0){
data <- na.omit(data[,c(colnames(r1$model),cluster)])
r1 <- lm(form, data)
}
X <- model.matrix(r1)
n <- dim(X)[1]
k <- dim(X)[2]
if(robust==FALSE & length(cluster)==0){
se <- sqrt(diag(solve(crossprod(X)) * as.numeric(crossprod(resid(r1))/(n-k))))
res <- cbind(coef(r1),se)
}
if(robust==TRUE){
u <- matrix(resid(r1))
meat1 <- t(X) %*% diag(diag(crossprod(t(u)))) %*% X
dfc <- n/(n-k)
se <- sqrt(dfc*diag(solve(crossprod(X)) %*% meat1 %*% solve(crossprod(X))))
res <- cbind(coef(r1),se)
}
if(length(cluster)!=0){
clus <- cbind(X,data[,cluster],resid(r1))
colnames(clus)[(dim(clus)[2]-1):dim(clus)[2]] <- c(cluster,"resid")
m <- dim(table(clus[,cluster]))
dfc <- (m/(m-1))*((n-1)/(n-k))
uclust <- apply(resid(r1)*X,2, function(x) tapply(x, clus[,cluster], sum))
se <- sqrt(diag(solve(crossprod(X)) %*% (t(uclust) %*% uclust) %*% solve(crossprod(X)))*dfc)
res <- cbind(coef(r1),se)
}
res <- cbind(res,res[,1]/res[,2],(1-pnorm(abs(res[,1]/res[,2])))*2)
res1 <- matrix(as.numeric(sprintf(paste("%.",paste(digits,"f",sep=""),sep=""),res)),nrow=dim(res)[1])
rownames(res1) <- rownames(res)
colnames(res1) <- c("Estimate","Std. Error","t value","Pr(>|t|)")
return(res1)
}
# with data as before
> ols(ceb ~ age + agefbrth + usemeth,children)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.358 0.174 7.815 0.000
age 0.224 0.003 64.888 0.000
agefbrth -0.261 0.009 -29.637 2.000
usemeth 0.187 0.055 3.380 0.001
> ols(ceb ~ age + agefbrth + usemeth,children,robust=T)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.358 0.168 8.105 0.000
age 0.224 0.005 47.993 0.000
agefbrth -0.261 0.010 -27.261 2.000
usemeth 0.187 0.061 3.090 0.002
> ols(ceb ~ age + agefbrth + usemeth,children,cluster="children")
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.358 0.425 3.197 0.001
age 0.224 0.032 7.101 0.000
agefbrth -0.261 0.035 -7.357 2.000
usemeth 0.187 0.094 1.986 0.047

Thanks for that. I don’t understand why the lm expression “r1 <- lm(form, data)" is a second time in the "if" though? Shouldn't it appear only once, after the first if?
Hey Joe,
Thanks for the comment.
The reason I did this was because sometimes there might be NA values in the cluster variable. This command trims the dataframe so there are no NA values.
Sure, but then why not do:
ols <- function(form, data, robust=FALSE, cluster=NULL,digits=3){
if(length(cluster)!=0){
data <- na.omit(data[,c(colnames(r1$model),cluster)])
}
r1 <- lm(form, data)
…
}
Otherwise it seems like you run the lm() twice when cluster is defined.
Sorry, my bad, I didn’t realise that you needed colnames(r1$model)… I must be low on caffeine.
Recently I took a stab at this topic myself [1], mainly showing off code for existing R implementations (using ‘plm’ and ‘sandwich’).
[1] http://landroni.wordpress.com/2012/06/02/fama-macbeth-and-cluster-robust-by-firm-and-time-standard-errors-in-r/
Interesting. Thanks for the comment!
Pingback: The Cluster Bootstrap « DiffusePrioR
Hi there,
I’m really happy that someone has written such nice code for doing robust and clustered SEs! I had trouble making the code work at first, and then realized that its because my X matrix wasn’t invertible. I just replaced `solve()’ with `ginv()’ (ginv() requires the `MASS’ package) everywhere in your `ols()’ function, and tried to replicate a published paper’s results and got exactly their results.
Is there any particular reason you chose to use `solve()’ instead of `ginv()’?
Thanks in advance
Hi Kaushik, this was a number of months ago, but I seem to remember having some problems with the ginv() function. I can’t remember what exactly they were unfortunately. Glad to hear it works for you though.
How difficult would it be to modify this code to handle weighting and clustering? e.g., estimate a FGLS model to account for mult. heteroskedasticity and cluster those standard errors by year.
Thanks! Great post.
Hi Nate, thanks for the comment. I am not sure I can help you with your problem. The approach I always take to calculating SEs in more complex models is to use a bootstrap, although I am not sure how applicable this is to your application.
I like this code, and I’ll try it out on my students tomorrow!
One minor issue in the code is that the output produces p-values greater than 1 for negative t-ratios. You can easily fix this by taking the absolute value of the t-ratio before calculating the p-values:
res <- cbind(res,res[,1]/res[,2],(1-pnorm(abs(res[,1]/res[,2])))*2)
Thanks for the help Garrett. I’ll fix that now.
Thank you so much for this.
Is there a way to extract the clustered standard errors to test for spatial dependence, for example?
I am not sure what you mean. What form are these data in? For example, do you have a lot of data that has the same geographic coordinates? If so, the clustered SEs will capture spatial clustering at this level.
Exactly, that is what i was looking for. I have firms nested in states. Thank you so much again, for this great post!
This is great! Do you have any suggestions on how to adapt this for a weighted regression?
Thanks
Helen
Hi Helen, thanks for the comment. You can use the multiwayvcov package for this. See the example below. Hope this helps!
library(multiwayvcov)
library(lmtest)
data(petersen)
m1 <- lm(y ~ x, data = petersen, weights = petersen$year)
# Cluster by firm
vcov_firm <- cluster.vcov(m1, petersen$firmid)
coeftest(m1, vcov_firm)