I don’t understand why any researcher would choose not to use panel/multilevel methods on panel/hierarchical data. Let’s take the following linear regression as an example:

where 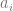


Let’s have a look at the consequences of this inefficiency using a simulation. I will simulate the following model:
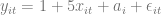
with 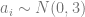
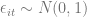
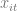
The graph below shows the importance of using panel methods over pooled OLS. It shows boxplots of the 100 simulated estimates. Even when the random effects assumption is violated, the random effects estimator (RE) is far superior to simple pooled OLS. Both the CRE and FE estimators perform well. Both have lowest root mean square errors, even though the model satisfies the random effects assumption. Please see my R code below.

# clear ws
rm(list=ls())
# load packages
library(lme4)
library(plyr)
library(lfe)
library(reshape)
library(ggplot2)
# from this:
### set number of individuals
n = 200
# time periods
t = 5
### model is: y=beta0_{i} +beta1*x_{it} + e_{it}
### average intercept and slope
beta0 = 1.0
beta1 = 5.0
### set loop reps
loop = 100
### results to be entered
results1 = matrix(NA, nrow=loop, ncol=4)
results2 = matrix(NA, nrow=loop, ncol=4)
for(i in 1:loop){
# basic data structure
data = data.frame(t = rep(1:t,n),
n = sort(rep(1:n,t)))
# random effect/intercept to add to each
rand = data.frame(n = 1:n,
a = rnorm(n,0,3))
data = join(data, rand, match="first")
# random error
data$u = rnorm(nrow(data), 0, 1)
# regressor x
data$x = runif(nrow(data), 0, 1)
# outcome y
data$y = beta0 + beta1*data$x + data$a + data$u
# make factor for i-units
data$n = as.character(data$n)
# group i mean's for correlated random effects
data$xn = ave(data$x, data$n, FUN=mean)
# pooled OLS
a1 = lm(y ~ x, data)
# random effects
a2 = lmer(y ~ x + (1|n), data)
# correlated random effects
a3 = lmer(y ~ x + xn + (1|n), data)
# fixed effects
a4 = felm(y ~ x | n, data)
# gather results
results1[i,] = c(coef(a1)[2],
coef(a2)$n[1,2],
coef(a3)$n[1,2],
coef(a4)[1])
### now let random effects assumption be false
### ie E[xa]!=0
data$x = runif(nrow(data), 0, 1) + 0.2*data$a
# the below is like above
data$y = beta0 + beta1*data$x + data$a + data$u
data$n = as.character(data$n)
data$xn = ave(data$x, data$n, FUN=mean)
a1 = lm(y ~ x, data)
a2 = lmer(y ~ x + (1|n), data)
a3 = lmer(y ~ x + xn + (1|n), data)
a4 = felm(y ~ x | n, data)
results2[i,] = c(coef(a1)[2],
coef(a2)$n[1,2],
coef(a3)$n[1,2],
coef(a4)[1])
}
# calculate rmse
apply(results1, 2, function(x) sqrt(mean((x-5)^2)))
apply(results2, 2, function(x) sqrt(mean((x-5)^2)))
# shape data and do ggplot
model.names = data.frame(X2 = c("1","2","3","4"),
estimator = c("OLS","RE","CRE","FE"))
res1 = melt(results1)
res1 = join(res1, model.names, match="first")
res2 = melt(results2)
res2 = join(res2, model.names, match="first")
res1$split = "RE Valid"
res2$split = "RE Invalid"
res1 = rbind(res1, res2)
res1$split = factor(res1$split, levels = c("RE Valid", "RE Invalid"))
res1$estimator = factor(res1$estimator, levels = c("OLS","RE","CRE","FE"))
number_ticks = function(n) {function(limits) pretty(limits, n)}
ggplot(res1, aes(estimator, value)) +
geom_boxplot(fill="lightblue") +
#coord_flip() +
facet_wrap( ~ split, nrow = 2, scales = "free_y") +
geom_hline(yintercept = 5) +
scale_x_discrete('') +
scale_y_continuous(bquote(beta==5), breaks=number_ticks(3)) +
theme_bw() +
theme(axis.text=element_text(size=16),
axis.title=element_text(size=16),
legend.title = element_blank(),
legend.text = element_text(size=16),
strip.text.x = element_text(size = 16),
axis.text.x = element_text(angle = 45, hjust = 1))
ggsave("remc.pdf", width=8, height=6)

Pingback: Distilled News | Data Analytics & R
Very interesting article. Are there any advantages in lmer(y ~ x + (1|n), data) over lm(y ~ x + factor(n), data)? I see the same root mean square error rate for both models in case of uncorrelated regressor and lm performs better in case of violated assumption.
Yes, there is. If you look at some of Andrew Gelman’s work on multilevel models he says the lmer gives you partial pooling rather than complete pooling (lm with factor). Lm with factor can overfit the intercepts. Look at his example with radon data to see this.